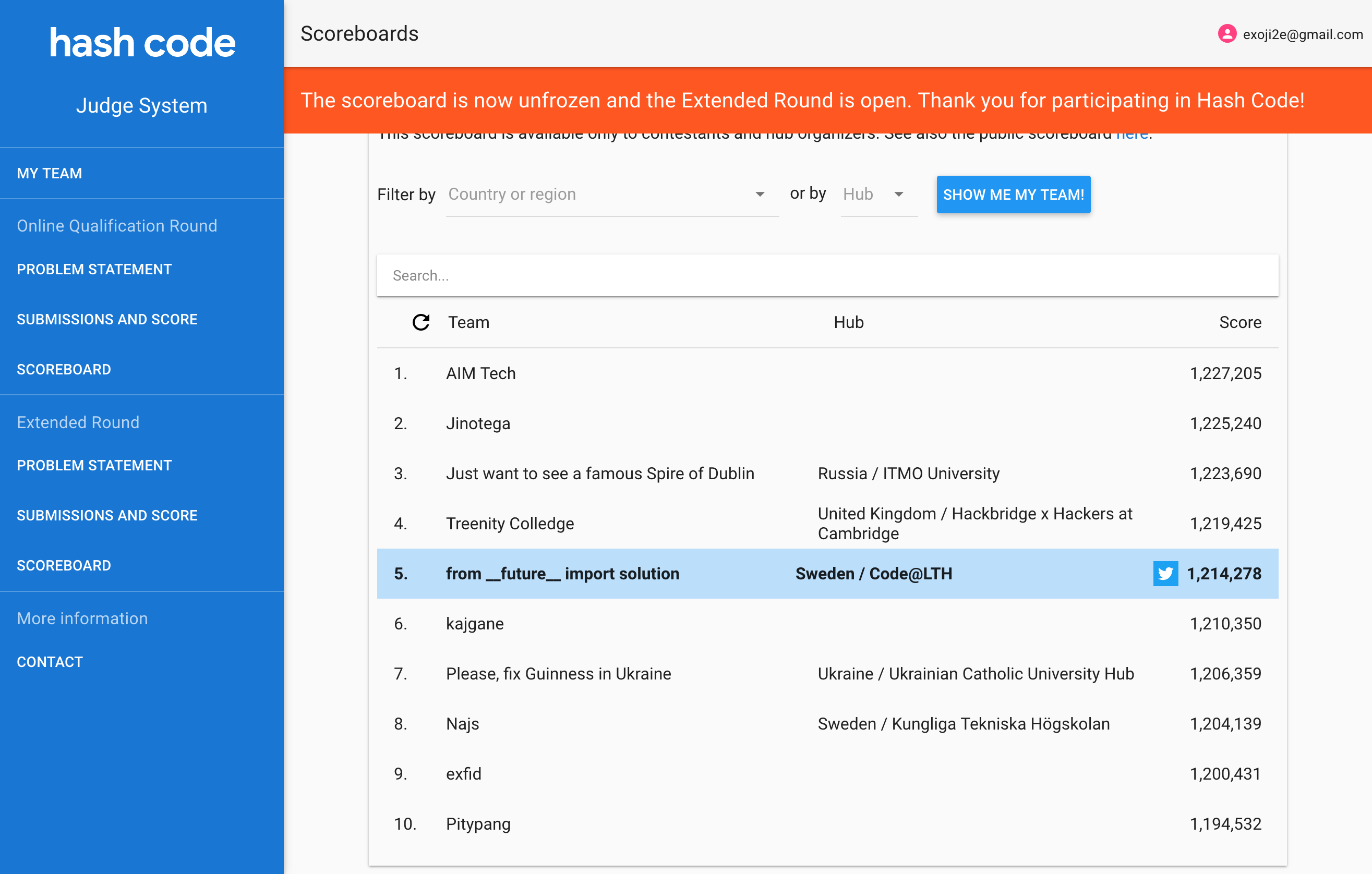
Yesterday evening the qualification round of Google HashCode took place! It’s a world wide team programming competition organized by Google. My team from __future__ import solution, consisting of me, Björn Magnusson, Jonatan Nilsson and Lars Åström, placed 5th globally out of 6500 teams! Almost everything went our way during the competition.
We also got covered in local media:
I have organized hubs for this competition with Code@LTH since 2016. A hub is a physical place where teams meet up and participate from the same location, with common fika.
This year 19 teams consisting of 60 participants visited the Code@LTH-hub!
The problem this year was to create a slide show of pictures that was as nice as possible. Each picture had a set of tags, like cat, sunset or jacket. You got points for every transition of images in the slide show, dependent on how many tags were in common and how many tags were unique for each picture. Formally: for a transition we got the score min(|t1| - |t1&t2|, |t1&t2|, |t2| - |t1&t2|) where t1 and t2 were the set of tags of the two images, t1&t2 is the intersection, and |t1| denotes the size of t1.
We were very fast (40 minutes) of creating a naive solution that scored a reasonable amount of points, by just picking an image, and then finding the best out of 100 random images, proceeding to the next one, until there were no images left.
Right, I forgot to mention that some images were vertical, and that each needed to be paired with another vertical image before they could be placed in the slide show, which made the problem significantly harder. The tags of such a slide became the union of the vertical images tags.
We got a very good idea for how to combine the vertical images by first searching for a vertical image that overlaps as much as possible with the previously picked slide, and then one that overlaps as little as possible. When we checked vertical images we just picked the best out of k random images. When we increased k from 100 to 1000 our score increased by 40%. We then checked versus all available vertical images. This code ran for over an hour, but increased our score with 80% compared to the solution with k=100.
We were leading the scoreboard for about 20 minutes, which was very exciting.
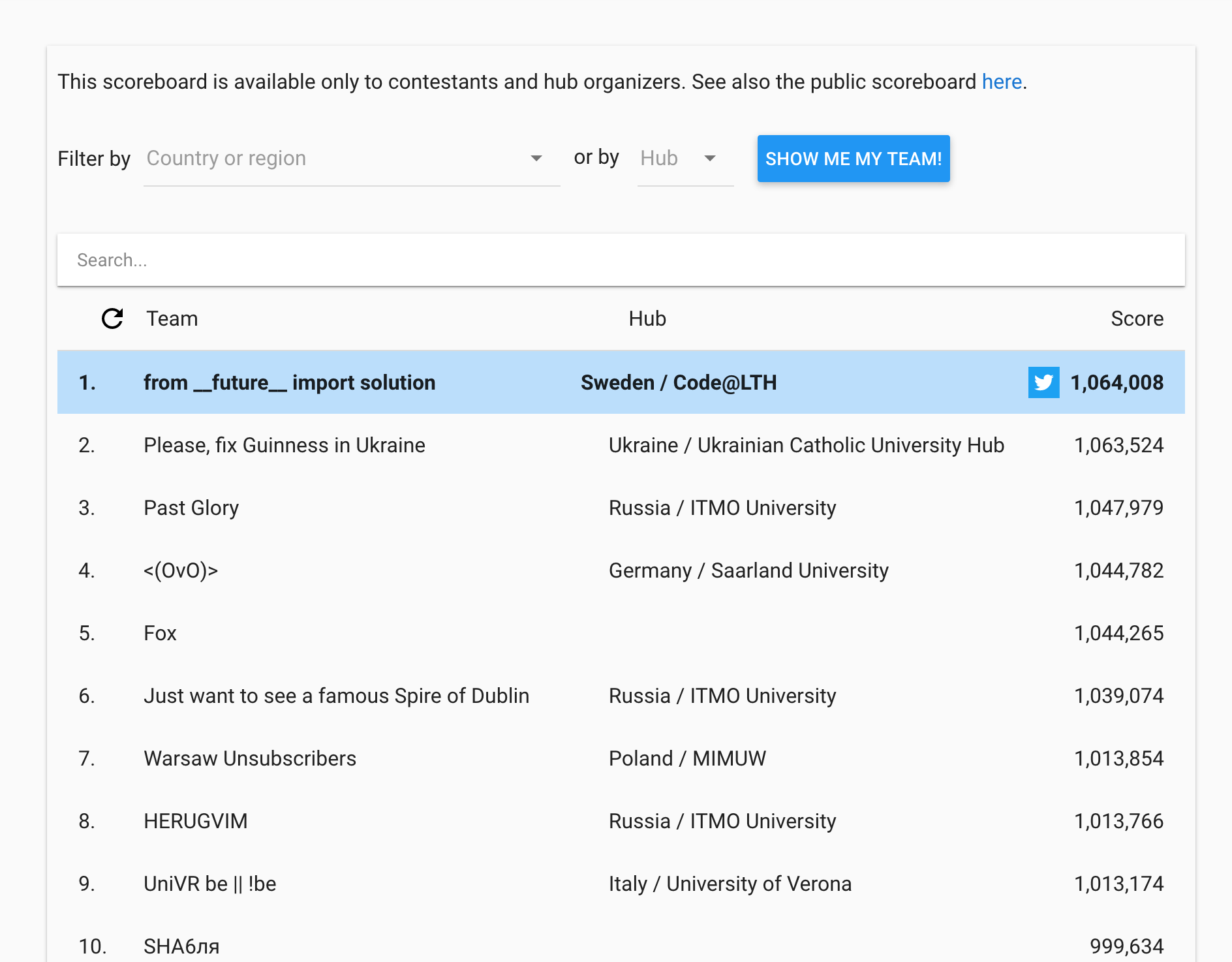

A great deal of this success is due to the preparation we have put into this. We have practiced on previous Hash Code competitions twice, and also put a lot of work into a template that helped us get stuff working very fast in the beginning of the competition. We look very much forward to the final round in Dublin the 27th of April!